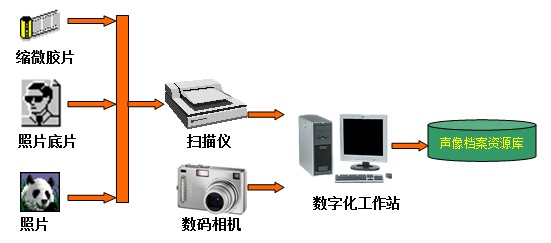
学籍档案是学校对学生在校期间进行管理、考核时直接形成的具有保存价值的历史记录。高校是培养高级人才的基地,学生学籍档案是高校档案馆重要的馆藏资源。本文所指的学籍档案数据库是以个人为单位组卷的学籍袋,主要包括毕业照、学生学籍表、学生成绩表、毕业资格审查表等材料。
一、学籍档案数据库的意义
档案数据库可分为全文数据库和目录数据库。而学籍档案数据库由原文数据库和学生信息数据库组成,两者以学生的学号作为唯一标识建立联结。原文数据库储存学籍档案原件的扫描文件,对原始的学籍材料进行数字化处理,具体地说,就是通过扫描仪把档案原文以图像文件的形式有序地存入计算机,通过检索就能直接在计算机上调阅档案信息。学生信息数据库存放所有学生的个人信息,一人一条记录,每个输入字段都作为查询检索的入口,实现学籍档案的自动化管理,也便于学生个人信息的统计,提高学籍档案的查全率、查准率和检索速度。以上两种数据库是构建学籍档案数据库首先要面对的问题,也是构成学籍档案数据库必不可少的条件,两者相结合才能实现真正意义上的学籍档案数字化。
建立学籍档案数据库,从狭义上说,就是建立学籍档案原文数据库和学生信息库,从广义上来说,更需进一步在两者之间建立一定的联系,只有这样,才能从大量原始文件中快速地调阅所需的内容。所以,必须设计一个学籍档案数据库管理系统,对所有的数据进行有效的管理。形象地说,就好比是造房子,根据使用功能将房子分隔成不同的房间,将每件物品分类放入相应的房间,如果需要使用某件物品,可根据功能分类,快速找到物品的存放地。数据库管理系统就象是管理整幢房子的物业管理员,它管理着计算机里的数据,即排列无序的扫描文件。
建立学籍档案数据库就等于实现了学籍档案的数字化。档案数据库的建立是网络时代的要求,也是建设数字化档案馆的必由之路。学籍档案数字化是实现数字化档案馆一个重要步骤,也为其它门类档案的数字化提供了一种可行的模式。
二、建立学籍档案数据库的必要性
1.建立学籍档案数据库使学籍档案的管理效率、检索速度和查准率有了明显的提高。面对日积月累的档案,沿用传统的手工目录查询档案已经不能适应形势的要求,传统的案卷目录检索点单一,不支持模糊查询,检索起来费劲费时,而且查全率和查准率很难得到保障。以复旦大学1960年以后形成的学生学籍档案为例,如本专科生的学生成绩表、毕业生登记表,不以个人为单位立卷的,而是以年度、院系或专业为单位装订成册,学生的学籍变更如休学、退学、复学、转学不能在案卷目录上体现出来,这样难免会降低档案的查准率。我们将学生的个人信息输入计算机,建立学生信息数据库,只要定义任一检索条件或组合查询,即可迅速准确地筛选出符合条件的记录。
2.采用学籍档案数据库管理缓解了档案保存与利用之间的矛盾。学籍档案的形成年度跨度较大,尤其是具有百年历史的高校,学籍档案对于研究高校教育史具有重要的参考价值,而档案不同于一般的历史文物,具有记录性和原始性的特点,随着社会的发展,学籍档案的利用率在不断提高,档案的破损速度也在加快,这样就产生了学籍档案“保存”与“利用”之间的矛盾。将学籍档案原文数字化,存入数据库,不仅可以解决“保存”与“利用”的矛盾,而且还大大提高了查检速度。
3.学籍档案数字化是档案信息上网的基础。网络化已成为时代的主旋律,网络技术的应用更推动了档案事业迈上新的层次。档案信息是重要的信息资源,档案信息只有上网才能体现它的价值,才能为更多人所利用。大量的档案信息寓于纸质的案卷、文件之中,虽然电子文件已经达到相当程度的普及,但大量较早时期形成的档案都还是纸质的,这是档案信息上网的一大障碍。只有将这些纸质档案转化为电子文件,才能真正成为电子信息。
三、建设学籍档案数据库
1.学生信息数据库的基本结构
学生信息数据库由10个输入字段组成,分别是:学号、姓名、字、号、籍贯、院、系、专业、入学年月、毕业年月,同时,这些字段又是多途径组合查询的检索入口。
我们用Access2000来开发学籍档案信息管理系统,Access是一种关系型数据库,它为用户提供了数据库管理的工具集和应用程序开发环境,是中小型数据库应用领域中最通用的数据库软件。由于Access数据库和VB(Visual Basic)语言结合得比较好,对于数据库开发人员,利用VB语言以及Access数据库提供的可视化工具和向导,便可以设计出具有一定规模、功能强大的数据库应用系统。Access还具有数据访问的功能,可以创建用来添加、编辑、查看、处理学籍档案数据库当前记录的Web页,也可以通过电子邮件发送数据。
2.制作扫描文件
采用扫描录入方式将学籍档案按原貌逐页存储为图像文件,学籍档案原件有5项基本内容:毕业照、学生学籍表、分年课程学分表、毕业资格审查表、中学毕业证书,以学号作为文件名标识,例如某人学号为13561,那么他的扫描文件分别为13561a、13561b、13561c、13561d、13561e,依次类推。
计算机图像文件的格式很多,常见的图像格式有:BMP、JPEG、TIFF等,使用上各有长短。不同的格式其文件大小、打开速度、支持颜色、压缩耗损等参数均不相同。BMP格式的图像没有压缩、最能体现实物的原貌,大多数浏览器如IE、Netscape等都支持这种格式。然而其文件大,占用系统资源最多,打开速度慢,特别是在网络上传输时,其打开和下载速度更难适应要求。因此在图像格式的选择上必须考虑Web图像的要求。JPEG格式的图像压缩比例大,图像文件做得小,网络下载速度也最快,支持颜色也多。TIFF格式的文件适合做动态图形,但是色彩层次的还原性比较差。所以,建设大量图片形式的扫描文件库选择以*.JPG格式保存比较好。
经过比较和测试,用100dpi的扫描分辨率扫描的图像在清晰度和文件大小之间达到较好的平衡。
3.学籍档案数据库系统的设计
对所有的扫描文件编制目录索引,目录索引用数据库方式建立,每一图像文件以其存储地址与其在目录索引中的记录相链接。利用目录索引可检出所需档案之图像文件的存放地址,通过地址借助链接显示该档案原文的图像。
我们设计的复旦大学学生学籍档案信息管理系统由数据库文件,扫描文件,超文本文件及程序文件组成。分别开设四个子目录存放这四部分的文件。
数据库文件即学籍信息数据库,由手工录入的学生信息组成,一人一条记录,是检索的依据,也是链接的基础。
扫描文件即学籍档案的原文扫描件,由于数量多,必需用一个大容量的硬盘来存放,为了保证数据的安全,还应分期分批进行数据备份。
超文本文件即*.html文件,通过程序生成,通过学号建立超文本链接。
程序文件由输入界面、查询界面组成,并分别嵌入IE控件。程序启动后,历读学籍档案文件夹中的扫描图形文件,依学号自动编写相应的HTML文件,供输入、查询中的浏览器阅读。
系统采用先扫描后输入的方式。在输入界面内,选择学号,程序调用对应的HTML文件,浏览器显示对应学籍表,依据学籍表输入相关信息,使数据库的输入工作简洁直观,可方便完成数据的保存、编辑和打印等工作。
在查询界面内,可按各字段进行独立或组合检索,并在网页内给出结果集合。点击学号,浏览器给出该学生的全部档案资料。并可直接打印,邮寄各文件。
四、建设学籍档案数据库的难点和解决办法
1.学籍档案具有原始性的特点。虽然文档一体化管理在信息系统技术上已逐步走向成熟,但是大量归档后的文件却不能做到全部数字化。自动文字识别软件OCR技术的应用大大提高了数字化的效率,但是这种软件要求印刷体的规范化文字,而对历史档案原始资料中大量形形色色的手写字体很难识别。由于时代所限,早期形成的历史档案都是纸质的,这也是实现档案数字化的瓶颈。所以,通过扫描技术,将原始的学籍档案材料,转换为图像文件存储在计算机中,是一种比较现实可行的办法。通过学籍档案数据库可以快速调用原文数据库即扫描文件库中的文件,也省却了调卷的繁复。
2.学籍档案材料不统一。学籍档案是散页的,各种材料大小不一,有些材料甚至有缺损,在扫描时需要对有残缺和破损的照片在进行修补,我们可以用图像处理技术对扫描的图像文件进行加工,使之达到满意的效果。
3.建设学籍档案数据库数据库是一项费时的工作。学籍档案的原始性决定了它的数字化必须通过扫描来实现,而学籍材料的不统一性又降低了扫描的效率。这样,学籍档案的全部数字化在短时间是不可能实现的。数据库管理系统的功能完善需要测试,而系统测试需要一定数量的数据,也就是学籍档案的原件扫描件。短时间里,档案的完全数字化很难实现,因为扫描是一项费时的工作,而档案数字化最基础的工作也就是扫描。
建立学籍档案数据库是建设数字化档案馆的一种探索,按照办公自动化、档案信息化、保管科学化、利用现代化的要求,通过建立学籍档案数据库可以实现档案信息数字化,达到利用现代化的要求,并最终实现学生学籍档案的信息共享和有效利用。档案数据库的建立是网络时代的要求,也是档案工作现代化的主要标志。只有将档案全文信息数字化了,才能在网上公布,构建现代意义上的数字化档案馆,使档案用户在足不出户的情况下借助网络查阅档案,获取信息。
(严玲霞)